Fake News Classifier using TensorFlow
Develop and assess a fake news classifier using TensorFlow
The data for this blog post is taken from the article:
- Ahmed H, Traore I, Saad S. (2017) “Detection of Online Fake News Using N-Gram Analysis and Machine Learning Techniques. In: Traore I., Woungang I., Awad A. (eds) Intelligent, Secure, and DependableSystems in Distributed and Cloud Environments. ISDDC 2017. Lecture Notes in Computer Science, vol 10618. Springer, Cham (pp. 127-138).
The data can be accessed from Kaggle. Professor Philip Chodrow had done a small amount of data cleaning and performed a train-test-split. Hence, the dataset is ready to be used!
Import libraries
import numpy as np
import pandas as pd
import tensorflow as tf
import re
import string
from tensorflow.keras import layers
from tensorflow.keras import losses
from tensorflow import keras
from tensorflow.keras.layers.experimental.preprocessing import TextVectorization
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
import plotly.express as px
import plotly.io as pio
from plotly.io import write_html
pio.templates.default = "plotly_white"
# Check tensorflow version = 2.4
tf.__version__
'2.4.1'
Acquire Training Data
train_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_train.csv?raw=true"
train_df = pd.read_csv(train_url)
train_df
| Unnamed: 0 | title | text | fake | |
|---|---|---|---|---|
| 0 | 17366 | Merkel: Strong result for Austria's FPO 'big c... | German Chancellor Angela Merkel said on Monday... | 0 |
| 1 | 5634 | Trump says Pence will lead voter fraud panel | WEST PALM BEACH, Fla.President Donald Trump sa... | 0 |
| 2 | 17487 | JUST IN: SUSPECTED LEAKER and “Close Confidant... | On December 5, 2017, Circa s Sara Carter warne... | 1 |
| 3 | 12217 | Thyssenkrupp has offered help to Argentina ove... | Germany s Thyssenkrupp, has offered assistance... | 0 |
| 4 | 5535 | Trump say appeals court decision on travel ban... | President Donald Trump on Thursday called the ... | 0 |
| ... | ... | ... | ... | ... |
| 22444 | 10709 | ALARMING: NSA Refuses to Release Clinton-Lynch... | If Clinton and Lynch just talked about grandki... | 1 |
| 22445 | 8731 | Can Pence's vow not to sling mud survive a Tru... | () - In 1990, during a close and bitter congre... | 0 |
| 22446 | 4733 | Watch Trump Campaign Try To Spin Their Way Ou... | A new ad by the Hillary Clinton SuperPac Prior... | 1 |
| 22447 | 3993 | Trump celebrates first 100 days as president, ... | HARRISBURG, Pa.U.S. President Donald Trump hit... | 0 |
| 22448 | 12896 | TRUMP SUPPORTERS REACT TO DEBATE: “Clinton New... | MELBOURNE, FL is a town with a population of 7... | 1 |
22449 rows × 4 columns
train_df['title'].loc[0], train_df['text'].loc[0], train_df['fake'].loc[0]
("Merkel: Strong result for Austria's FPO 'big challenge' for other parties",
'German Chancellor Angela Merkel said on Monday that the strong showing of Austria s anti-immigrant Freedom Party (FPO) in Sunday s election was a big challenge for other parties. Speaking at a news conference in Berlin, Merkel added that she was hoping for close cooperation with Austria s conservative election winner Sebastian Kurz at the European level. ',
0)
- Each row: 1 article
titlecolumn: title of articletextcolumn: full article textfakecolumn: =0 if article is true; =1 if fake news (as determined by the authors of the paper above)
Make TensorFlow Dataset:
make_dataset function:
- Remove stopwords from article
textandtitle. (Stopword is usually considered to be uninformative, such as “the”, “and”, or “but”.) - Construct and Return a
tf.data.Datasetwith 2 inputs and 1 output. The input format = (title, text), output consist onlyfakecolumn.
# Download stopwords if needed
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
def make_dataset(df):
'''
Remove stopwords from article inputs `text` and `title`
Return a Tensor Dataset with 2 inputs and 1 output (`fake`)
'''
stop = stopwords.words('english')
df['title'] = df['title'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
df['text'] = df['text'].apply(lambda x: ' '.join([word for word in x.split() if word not in (stop)]))
data_set = tf.data.Dataset.from_tensor_slices((
{'title' : df[['title']], 'text' : df[['text']]}, # inputs
{'fake' : df[['fake']] } )) # output
data_set.batch(100) # batching --> cause model to train on chunks of data rather than individual rows
return data_set
data = make_dataset(train_df)
data
<TensorSliceDataset shapes: ({title: (1,), text: (1,)}, {fake: (1,)}), types: ({title: tf.string, text: tf.string}, {fake: tf.int64})>
Check the full length of the Tensor Dataset, it should be the same as our training set length (22449 rows)
len(data)
22449
Check the inputs and outputs contents:
for title, text in data.take(2):
print(title)
print(text)
print('')
{'title': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b"Merkel: Strong result Austria's FPO 'big challenge' parties"],
dtype=object)>, 'text': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b'German Chancellor Angela Merkel said Monday strong showing Austria anti-immigrant Freedom Party (FPO) Sunday election big challenge parties. Speaking news conference Berlin, Merkel added hoping close cooperation Austria conservative election winner Sebastian Kurz European level.'],
dtype=object)>}
{'fake': <tf.Tensor: shape=(1,), dtype=int64, numpy=array([0])>}
{'title': <tf.Tensor: shape=(1,), dtype=string, numpy=array([b'Trump says Pence lead voter fraud panel'], dtype=object)>, 'text': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b'WEST PALM BEACH, Fla.President Donald Trump said remarks broadcast Sunday would put Vice President Mike Pence charge commission probe believes voter fraud last November\'s election. There overwhelming consensus among state officials, election experts, politicians voter fraud rare United States, Trump repeatedly said thinks perhaps millions votes cast Nov. 8 election fraudulent. "I\'m going set commission headed Vice President Pence we\'re going look very, carefully," Trump told Fox News Channel\'s Bill O\'Reilly interview taped Friday. Trump, spending weekend Mar-a-Lago resort Palm Beach, Florida, captured presidency winning enough state-by-state Electoral College votes defeat Democrat Hillary Clinton. Still, Clinton popular vote nearly 3 million votes, piling overwhelming majority deeply Democratic states like California. This irked Trump result claimed voter fraud without evidence. Senate Majority Leader Mitch McConnell, Kentucky Republican, said \'s "State Union" election fraud occur "there evidence occurred significant number would changed presidential election." "And I think ought spend federal money investigating that. I think states take look issue," said.'],
dtype=object)>}
{'fake': <tf.Tensor: shape=(1,), dtype=int64, numpy=array([0])>}
Validation Data
Split 20% of dataset to use for validation. Hence 60% training, 20% validation, and 20% testing.
# shuffle to avoid any ordered bias
data = data.shuffle(buffer_size = len(data))
# initiate size for train and val, what is leftover is test size
train_size = int(0.6*len(data))
val_size = int(0.2*len(data))
train = data.take(train_size).batch(20)
val = data.skip(train_size).take(val_size).batch(20)
test = data.skip(train_size + val_size).batch(20)
len(train), len(val), len(test) # the length of each can be multiplied by batch size to give total length of Data
(674, 225, 225)
Create Models
The primary question:
When detecting fake news, is it most effective to focus on only the title of the article, the full text of the article, or both?
To address this question, create 3 TensorFlow models
- Only the article title as input
- Only the article text as input
- Both article title and article text as input
OVERVIEW
- Standardization: clean unstructured text by remove capitals and remove punctuation.
-
Vectorization: represent text as vector (array, tensor). In this tutorial, we will use frequency rank to replace each word in the data using
TextVectorizationfromtensorflow.keras.layers.experimental.preprocessing. (Check docs for more info). - Keras Functional API (to use distinct kinds of input)
- Inputs: specify different the 2 kinds of
keras.Inputfor the model. - Hidden Layers:
- Vectorized layer
- Embedding layer: representation of a word in vector space, such that words with related meanings are close to each other in a vector space, while words with different meanings are further apart.
- Pooling layer: reduce the size of data at each step
- Dropout layer: disable a fixed percentage of the units in each layer (only during training). Hence, reduce the risk of overfitting since the units are used during validation and testing, but not during training)
- Dense layer:
unitarguments controls shape of output. UseReLUas the activation function, but the last node for output usessigmoidactivation function due to the binary classification of thefakeoutput (contains 0 or 1 only).
- For The Embedding, create a shared layers.
- Concatenate the layers if using both inputs, if not, continue with 1
- Inputs: specify different the 2 kinds of
- Compile and Evaluate model
Preprocess Data
size_vocab = 2000
def standardization(input_data):
''' standardize data by removing capitals and punctuation '''
lowercase = tf.strings.lower(input_data)
no_punctuation = tf.strings.regex_replace(lowercase,
'[%s]' % re.escape(string.punctuation),'')
return no_punctuation
def vectorize_layer(train, feature):
''' create vectorize layers depend on input feature '''
vectorize_layer = TextVectorization(standardize = standardization,
max_tokens = size_vocab, # only consider this many words
output_mode = 'int',
output_sequence_length = 500)
vectorize_layer.adapt(train.map(lambda x, y: x[feature]))
return vectorize_layer
title_vectorize = vectorize_layer(train, 'title')
text_vectorize = vectorize_layer(train, 'text')
title_input = keras.Input(shape=(1,), name='title', dtype='string') # 1 entry for each article --> (1,)
text_input = keras.Input(shape=(1,), name='text', dtype='string')
1st model: Only title as input
Pipeline for title input
# shared embedding layer
shared_embedding = layers.Embedding(size_vocab, 30, name = 'embedding')
# layers for processing title
title_features = title_vectorize(title_input)
title_features = shared_embedding(title_features)
title_features = layers.GlobalAveragePooling1D()(title_features)
title_features = layers.Dropout(0.2)(title_features)
title_features = layers.Dense(32, activation='relu')(title_features)
title_output = layers.Dense(1, activation='sigmoid', name='fake')(title_features)
A peer told me to put 2 in this code instead:
title_output = layers.Dense(1, activation='sigmoid', name='fake')
I think I should add an explanation to that:
- The final connected layer in neural network receives the output from last layer features and compute a weighted sum of the vector value.
- Using sigmoid activation always returns a single value between 0 and 1, indicating the probability of an article being real news.
- Using ReLU (Rectified Linear U) will returns 0 if receives any negative input, but it return the positive value back as it is. Thus, its output ranges from 0 to infinity, which also to the number of target value (2). –> normally use
For binary target like this example of fake news (0 fake and 1 real news), throught articles, I believe that using sigmoid is better.
Read more here
title_model = keras.Model(inputs = [title_input], outputs = title_output)
title_model.summary()
Model: "model"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
title (InputLayer) [(None, 1)] 0
_________________________________________________________________
text_vectorization (TextVect (None, 500) 0
_________________________________________________________________
embedding (Embedding) (None, 500, 30) 60000
_________________________________________________________________
global_average_pooling1d (Gl (None, 30) 0
_________________________________________________________________
dropout (Dropout) (None, 30) 0
_________________________________________________________________
dense (Dense) (None, 32) 992
_________________________________________________________________
fake (Dense) (None, 1) 33
=================================================================
Total params: 61,025
Trainable params: 61,025
Non-trainable params: 0
_________________________________________________________________
keras.utils.plot_model(title_model) #to_file='title_model_pipeline.png')
Compile title_model
title_model.compile(optimizer = "adam",
loss = 'binary_crossentropy',
metrics=['accuracy'])
title_history = title_model.fit(train,
validation_data=val,
epochs = 10)
Epoch 1/10
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/functional.py:595: UserWarning:
Input dict contained keys ['text'] which did not match any model input. They will be ignored by the model.
674/674 [==============================] - 6s 7ms/step - loss: 0.6844 - accuracy: 0.5469 - val_loss: 0.4815 - val_accuracy: 0.9345
Epoch 2/10
674/674 [==============================] - 4s 6ms/step - loss: 0.3486 - accuracy: 0.9181 - val_loss: 0.1553 - val_accuracy: 0.9436
Epoch 3/10
674/674 [==============================] - 4s 6ms/step - loss: 0.1208 - accuracy: 0.9628 - val_loss: 0.0843 - val_accuracy: 0.9719
Epoch 4/10
674/674 [==============================] - 4s 6ms/step - loss: 0.0859 - accuracy: 0.9708 - val_loss: 0.0615 - val_accuracy: 0.9795
Epoch 5/10
674/674 [==============================] - 4s 6ms/step - loss: 0.0661 - accuracy: 0.9766 - val_loss: 0.0659 - val_accuracy: 0.9795
Epoch 6/10
674/674 [==============================] - 4s 6ms/step - loss: 0.0670 - accuracy: 0.9762 - val_loss: 0.0484 - val_accuracy: 0.9840
Epoch 7/10
674/674 [==============================] - 4s 6ms/step - loss: 0.0596 - accuracy: 0.9814 - val_loss: 0.0403 - val_accuracy: 0.9882
Epoch 8/10
674/674 [==============================] - 4s 6ms/step - loss: 0.0521 - accuracy: 0.9813 - val_loss: 0.0429 - val_accuracy: 0.9849
Epoch 9/10
674/674 [==============================] - 4s 6ms/step - loss: 0.0480 - accuracy: 0.9840 - val_loss: 0.0431 - val_accuracy: 0.9869
Epoch 10/10
674/674 [==============================] - 4s 6ms/step - loss: 0.0416 - accuracy: 0.9857 - val_loss: 0.0355 - val_accuracy: 0.9875
plt.plot(title_history.history['accuracy'], label = 'accuracy')
plt.plot(title_history.history['val_accuracy'], label = 'validation')
plt.legend()
# plt.savefig('title_model.png')
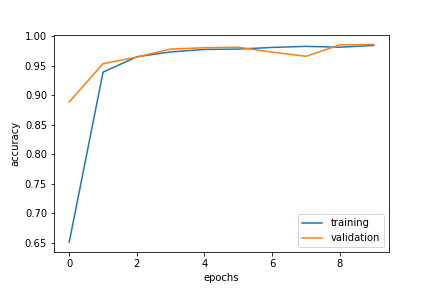
title_model.evaluate(test)
225/225 [==============================] - 1s 3ms/step - loss: 0.0413 - accuracy: 0.9864
[0.04134218394756317, 0.986417293548584]
Pipeline for text input
text_features = text_vectorize(text_input)
text_features = shared_embedding(text_features)
text_features = layers.GlobalAveragePooling1D()(text_features)
text_features = layers.Dropout(0.2)(text_features)
text_features = layers.Dense(32, activation='relu')(text_features)
text_output = layers.Dense(1, activation='sigmoid', name='fake')(text_features)
text_model = keras.Model(inputs = text_input, outputs = text_output)
text_model.summary()
Model: "model_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text (InputLayer) [(None, 1)] 0
_________________________________________________________________
text_vectorization_1 (TextVe (None, 500) 0
_________________________________________________________________
embedding (Embedding) (None, 500, 30) 60000
_________________________________________________________________
global_average_pooling1d_1 ( (None, 30) 0
_________________________________________________________________
dropout_1 (Dropout) (None, 30) 0
_________________________________________________________________
dense_1 (Dense) (None, 32) 992
_________________________________________________________________
fake (Dense) (None, 1) 33
=================================================================
Total params: 61,025
Trainable params: 61,025
Non-trainable params: 0
_________________________________________________________________
keras.utils.plot_model(text_model) #, to_file='text_model_pipeline.png')
text_model.compile(optimizer = "adam",
loss = 'binary_crossentropy',
metrics=['accuracy'])
text_history = text_model.fit(train,
validation_data=val,
epochs = 10)
Epoch 1/10
/usr/local/lib/python3.7/dist-packages/tensorflow/python/keras/engine/functional.py:595: UserWarning:
Input dict contained keys ['title'] which did not match any model input. They will be ignored by the model.
674/674 [==============================] - 7s 9ms/step - loss: 0.6442 - accuracy: 0.6215 - val_loss: 0.2646 - val_accuracy: 0.9432
Epoch 2/10
674/674 [==============================] - 6s 8ms/step - loss: 0.2469 - accuracy: 0.9246 - val_loss: 0.1338 - val_accuracy: 0.9664
Epoch 3/10
674/674 [==============================] - 6s 8ms/step - loss: 0.1639 - accuracy: 0.9499 - val_loss: 0.1053 - val_accuracy: 0.9737
Epoch 4/10
674/674 [==============================] - 5s 8ms/step - loss: 0.1286 - accuracy: 0.9623 - val_loss: 0.0955 - val_accuracy: 0.9699
Epoch 5/10
674/674 [==============================] - 5s 8ms/step - loss: 0.1112 - accuracy: 0.9660 - val_loss: 0.0728 - val_accuracy: 0.9822
Epoch 6/10
674/674 [==============================] - 5s 8ms/step - loss: 0.0862 - accuracy: 0.9724 - val_loss: 0.0709 - val_accuracy: 0.9773
Epoch 7/10
674/674 [==============================] - 6s 8ms/step - loss: 0.0837 - accuracy: 0.9725 - val_loss: 0.0599 - val_accuracy: 0.9831
Epoch 8/10
674/674 [==============================] - 6s 8ms/step - loss: 0.0742 - accuracy: 0.9776 - val_loss: 0.0582 - val_accuracy: 0.9793
Epoch 9/10
674/674 [==============================] - 6s 8ms/step - loss: 0.0588 - accuracy: 0.9814 - val_loss: 0.0447 - val_accuracy: 0.9873
Epoch 10/10
674/674 [==============================] - 6s 8ms/step - loss: 0.0540 - accuracy: 0.9823 - val_loss: 0.0442 - val_accuracy: 0.9882
plt.plot(text_history.history['accuracy'], label = 'accuracy')
plt.plot(text_history.history['val_accuracy'], label = 'validation')
plt.legend()
# plt.savefig('text_model.png')
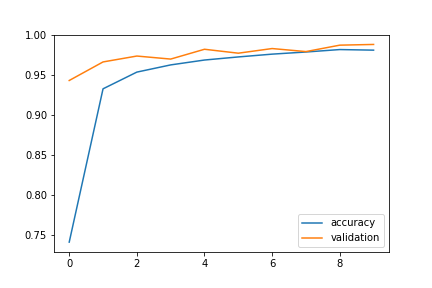
text_model.evaluate(test)
225/225 [==============================] - 1s 5ms/step - loss: 0.0472 - accuracy: 0.9878
[0.04717394337058067, 0.9877532720565796]
Pipeline for (title, text)
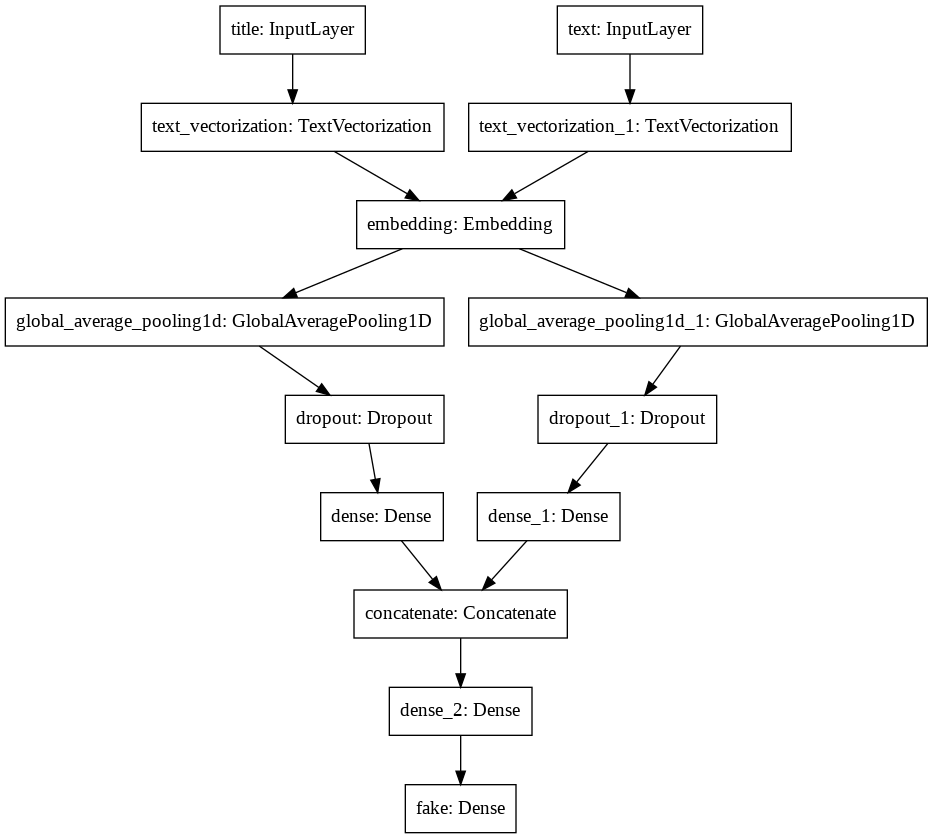
main = layers.concatenate([title_features, text_features], axis=1)
main = layers.Dense(32, activation='relu')(main)
main_output = layers.Dense(1, activation='sigmoid', name = "fake")(main)
model = keras.Model(inputs = [title_input, text_input],
outputs = main_output)
model.summary()
Model: "model_2"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
title (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
text (InputLayer) [(None, 1)] 0
__________________________________________________________________________________________________
text_vectorization (TextVectori (None, 500) 0 title[0][0]
__________________________________________________________________________________________________
text_vectorization_1 (TextVecto (None, 500) 0 text[0][0]
__________________________________________________________________________________________________
embedding (Embedding) (None, 500, 30) 60000 text_vectorization[0][0]
text_vectorization_1[0][0]
__________________________________________________________________________________________________
global_average_pooling1d (Globa (None, 30) 0 embedding[0][0]
__________________________________________________________________________________________________
global_average_pooling1d_1 (Glo (None, 30) 0 embedding[1][0]
__________________________________________________________________________________________________
dropout (Dropout) (None, 30) 0 global_average_pooling1d[0][0]
__________________________________________________________________________________________________
dropout_1 (Dropout) (None, 30) 0 global_average_pooling1d_1[0][0]
__________________________________________________________________________________________________
dense (Dense) (None, 32) 992 dropout[0][0]
__________________________________________________________________________________________________
dense_1 (Dense) (None, 32) 992 dropout_1[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 64) 0 dense[0][0]
dense_1[0][0]
__________________________________________________________________________________________________
dense_2 (Dense) (None, 32) 2080 concatenate[0][0]
__________________________________________________________________________________________________
fake (Dense) (None, 1) 33 dense_2[0][0]
==================================================================================================
Total params: 64,097
Trainable params: 64,097
Non-trainable params: 0
__________________________________________________________________________________________________
keras.utils.plot_model(model) #, to_file='main_model_pipeline.png')
model.compile(optimizer = "adam",
loss = 'binary_crossentropy',
metrics=['accuracy'])
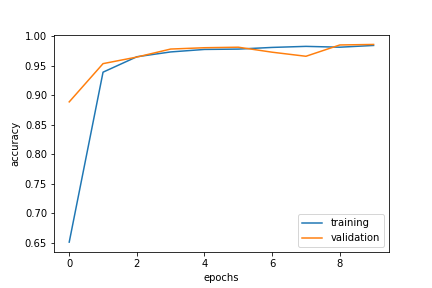
history = model.fit(train, validation_data=val, epochs = 10)
Epoch 1/10
674/674 [==============================] - 8s 11ms/step - loss: 0.1204 - accuracy: 0.9608 - val_loss: 0.0110 - val_accuracy: 0.9969
Epoch 2/10
674/674 [==============================] - 7s 10ms/step - loss: 0.0134 - accuracy: 0.9966 - val_loss: 0.0057 - val_accuracy: 0.9987
Epoch 3/10
674/674 [==============================] - 7s 11ms/step - loss: 0.0091 - accuracy: 0.9976 - val_loss: 0.0061 - val_accuracy: 0.9984
Epoch 4/10
674/674 [==============================] - 7s 10ms/step - loss: 0.0084 - accuracy: 0.9971 - val_loss: 0.0085 - val_accuracy: 0.9967
Epoch 5/10
674/674 [==============================] - 7s 11ms/step - loss: 0.0073 - accuracy: 0.9979 - val_loss: 0.0044 - val_accuracy: 0.9989
Epoch 6/10
674/674 [==============================] - 8s 11ms/step - loss: 0.0116 - accuracy: 0.9967 - val_loss: 0.0026 - val_accuracy: 0.9996
Epoch 7/10
674/674 [==============================] - 7s 11ms/step - loss: 0.0055 - accuracy: 0.9987 - val_loss: 0.0024 - val_accuracy: 0.9989
Epoch 8/10
674/674 [==============================] - 7s 10ms/step - loss: 0.0058 - accuracy: 0.9979 - val_loss: 0.0027 - val_accuracy: 0.9989
Epoch 9/10
674/674 [==============================] - 7s 10ms/step - loss: 0.0047 - accuracy: 0.9986 - val_loss: 9.4454e-04 - val_accuracy: 1.0000
Epoch 10/10
674/674 [==============================] - 7s 10ms/step - loss: 0.0047 - accuracy: 0.9989 - val_loss: 0.0047 - val_accuracy: 0.9980
plt.plot(history.history['accuracy'], label = 'accuracy')
plt.plot(history.history['val_accuracy'], label = 'validation')
plt.legend()
# plt.savefig('both_model.png')
model.evaluate(test)
225/225 [==============================] - 1s 5ms/step - loss: 0.0047 - accuracy: 0.9987
[0.004715826828032732, 0.9986640214920044]
Model Evaluation
The model with both inputs gave 99.6% accuracy, hence, best model.
Now, test model on unseen data and evaluate its performance
test_url = "https://github.com/PhilChodrow/PIC16b/blob/master/datasets/fake_news_test.csv?raw=true"
test_df = pd.read_csv(test_url)
test_df
| Unnamed: 0 | title | text | fake | |
|---|---|---|---|---|
| 0 | 420 | CNN And MSNBC Destroy Trump, Black Out His Fa... | Donald Trump practically does something to cri... | 1 |
| 1 | 14902 | Exclusive: Kremlin tells companies to deliver ... | The Kremlin wants good news. The Russian lead... | 0 |
| 2 | 322 | Golden State Warriors Coach Just WRECKED Trum... | On Saturday, the man we re forced to call Pre... | 1 |
| 3 | 16108 | Putin opens monument to Stalin's victims, diss... | President Vladimir Putin inaugurated a monumen... | 0 |
| 4 | 10304 | BREAKING: DNC HACKER FIRED For Bank Fraud…Blam... | Apparently breaking the law and scamming the g... | 1 |
| ... | ... | ... | ... | ... |
| 22444 | 20058 | U.S. will stand be steadfast ally to Britain a... | The United States will stand by Britain as it ... | 0 |
| 22445 | 21104 | Trump rebukes South Korea after North Korean b... | U.S. President Donald Trump admonished South K... | 0 |
| 22446 | 2842 | New rule requires U.S. banks to allow consumer... | U.S. banks and credit card companies could be ... | 0 |
| 22447 | 22298 | US Middle Class Still Suffering from Rockefell... | Dick Eastman The Truth HoundWhen Henry Kissin... | 1 |
| 22448 | 333 | Scaramucci TV Appearance Goes Off The Rails A... | The most infamous characters from Donald Trump... | 1 |
22449 rows × 4 columns
test_data = make_dataset(test_df)
for input, output in test_data.take(5):
print(input)
print(output)
print('')
{'title': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b'CNN And MSNBC Destroy Trump, Black Out His Fact-Free Tax Reform Speech (TWEET)'],
dtype=object)>, 'text': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b'Donald Trump practically something criticize media fake news almost daily basis, two major news networks turned tables put blast major way.The White House currently arms recent decision MSNBC, decided air Trump insanely dishonest North Dakota speech earlier today. Trump supposed address tax reform speech, major problem saying word true. In response fact-free speech, MSNBC decided irresponsible air speech decided spare Americans misinformation nonsense.Once Trump administration found move press, White House practically threw hissy fit. Special Assistant President Assistant White House Communications Director Steven Chueng tweeted:Instead insulting viewers Trump lies, MSNBC Nicole Wallace reported important, truthful topics DACA Russia. Jake Tapper focused Hurricane Irma, Russia, debt ceiling Trump spewed usual nonsense.This major f*ck Trump administration sends strong message dishonest narrative administration continues put American people tolerated. While people likely going react strongly topic dry tax reform, two major networks refusing air speech big deal. Trump desperately wants needs coverage, obviously pissed eyes him. If cable news networks break Trump, already failing presidency even danger.Featured screenshot'],
dtype=object)>}
{'fake': <tf.Tensor: shape=(1,), dtype=int64, numpy=array([1])>}
{'title': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b'Exclusive: Kremlin tells companies deliver good news'],
dtype=object)>, 'text': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b'The Kremlin wants good news. The Russian leadership told major companies supply news stories put stewardship country positive light, according documents seen . A seven-page document spelled kind articles required, focus new jobs, scientific achievements new infrastructure, especially involving state support. It also detailed stories presented, gave weekly deadline submissions. The instructions sent last month energy ministry 45 companies Russia energy utilities sector including Rosneft, Lukoil Novatek, according second document, list recipients. The drive coincides run-up presidential election March next year President Vladimir Putin needs strong mandate high turnout maintain firm grip power dominating Russian politics two decades. Life majority people become calmer, comfortable, attractive. But many examples often escape media attention, said first document. Our task, creative painstaking approach, select topics subjects offer media. That document, mention election, said news items supplied feed positive news correspond two themes: Life getting better How things were; . Both documents attached invitation, dated Oct. 9, sent energy ministry senior executives public relations government relations departments firms, 17 state-controlled 28 privately-held. The invitation requested send representatives Oct. 12 meeting ministry Moscow discuss help government PR effort. saw copy invitation spoke three executives received it. According invitation, news initiative requested Sergei Kiriyenko, first deputy chief staff presidential administration. A spokesman Kiriyenko respond request comment. The energy ministry also respond, Kremlin spokesman Dmitry Peskov. sent requests comment biggest five companies 45, market value - state-owned oil major Rosneft, state-owned gas giant Gazprom, private oil companies Lukoil Surgutneftegaz, private gas firm Novatek. No responses received. NINE-POINT LIST Oil gas provide Russia biggest source revenue energy firms among powerful companies biggest employers. found evidence similar instructions sent companies sectors. The Oct. 12 meeting chaired Deputy Energy Minister Anton Inyutsyn, official presidential administration also present, according one sources attended. The two officials went explained instructions laid seven-page document, said source, added election mentioned. reported February ministry enlisted energy companies give advance notice developments could influence public opinion. The meeting last month guidelines circulated preparation show that, since then, initiative stepped higher gear, companies handed highly specific instructions expected help. It clear companies acted instructions. The news guidelines document said government wanted highlight victories achievements . It included nine-point list kind news companies supply. It asked, example, stories business units possible say state support helped lift crisis, restored modern production, re-equipped new equipment gave work local residents . Examples given kind events interest government elsewhere corporate world included state lender Sberbank hiring 700 people Volga river city Togliatti, festival funded company Kaliningrad region young people hearing difficulties sports center opened Cherkessk, southern Russia. The document also held case Yevgeny Kosmin example positive news story, miner western Siberia whose team extracted 1.6 million tonnes coal July year, monthly record. That carried echoes Alexey Stakhanov, miner 1935 extracted almost 15 times coal shift quota required. Communist propaganda held Stakhanov symbol Soviet industrial prowess. The instructions stipulated companies submit positive news stories every week - Monday, Tuesday morning latest. They said companies present items format table, new additions highlighted colored font, accompanied press release could passed journalists minimal editing government officials. The document also required company provide contact person could provide extra information journalists, tell TV news crews reach venue report event, organize access news crews company sites. able establish Kremlin made similarly specific demands companies past. Putin yet declared intention seek re-election. Most Kremlin observers say will. Opinion polls show win comfortably, many voters crediting restoring national pride. The Kremlin biggest headache election, scheduled next March, ensuring strong turnout, say many political analysts. With economy weak many people viewing result foregone conclusion, voters may tempted stay away polling stations. A low turnout could undermine Putin legitimacy next term, analysts say.'],
dtype=object)>}
{'fake': <tf.Tensor: shape=(1,), dtype=int64, numpy=array([0])>}
{'title': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b'Golden State Warriors Coach Just WRECKED Trump After Attack On One Of His Players'],
dtype=object)>, 'text': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b"On Saturday, man forced call President Trump responded Golden State Warriors star Stephen Curry refusal accept invitation White House internet equivalent incoherently screeching WELL FINE, YOU RE NOT INVITED ANYWAY. Going White House considered great honor championship team.Stephen Curry hesitating,therefore invitation withdrawn! Donald J. Trump (@realDonaldTrump) September 23, 2017Unfortunately Trump, Warriors coach Steve Kerr Curry back. The idea civil discourse guy tweeting demeaning people saying things saying sort far-fetched, Kerr said Sunday. Can picture us really civil discourse him? It actual chance talk president, said. After all, works us. He public servant. He may aware that, public servant, right? So maybe NBA champions, people prominent position, could go say, This bothering us, this?' Then laid Trump attacking black football players exercising First Amendment rights calling Nazis fine people: How irony Free speech fine neo-Nazi chanting hate slogans, free speech allowed kneel protest? No matter many times football player says, I honor military, I protesting police brutality racial inequality, matter. Nationalists saying, You disrespecting flag. Well, know else disrespectful flag? Racism. And one way worse other. Trump constant embarrassment country.Watch Kerr rip apart below:Featured screen capture"],
dtype=object)>}
{'fake': <tf.Tensor: shape=(1,), dtype=int64, numpy=array([1])>}
{'title': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b"Putin opens monument Stalin's victims, dissidents cry foul"],
dtype=object)>, 'text': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b'President Vladimir Putin inaugurated monument victims Stalinist purges Monday, Soviet-era dissidents accused cynicism time say authorities riding roughshod civil freedoms. The Wall Grief occupies space edge Moscow busy 10-lane ring road depicts mass faceless victims, many sent prison camps executed Josef Stalin watch falsely accused enemies people. Nearly 700,000 people executed Great Terror 1937-38, according conservative official estimates. An unequivocal clear assessment repression help prevent repeated, Putin said opening ceremony. This terrible past must erased national memory cannot justified anything. His words ceremony amounted one strongest condemnations Soviet Union dark side 18 years dominated Russia political landscape. Putin past called Stalin complex figure said attempts demonise ploy attack Russia. But Monday ceremony, said lessons Russia. It mean demanding accounts settled, said Putin, stressed need stability. We must never push society dangerous precipice division. Putin carefully balanced words reflect Kremlin unease year centenary 1917 Bolshevik Revolution, paved way Stalin rise. Uncomfortable promoting discussion idea governments overthrown force, Kremlin organizing commemorative events. Putin, expected run win presidency March, told human rights activists earlier Monday hoped centenary would allow society draw line tumultuous events 1917 accept Russia history - great victories tragic pages . Yet historians fret say Putin ambiguity Stalin along Russia 2014 annexation Ukraine Crimea emboldened Stalin admirers. Monuments memorial plaques honoring Stalin sprung different Russian regions. State-approved textbooks softened , opinion poll June crowned country outstanding historical figure. By contrast, helped document Stalin crimes, Memorial human rights group individual historians journalists, sometimes felt pressure authorities. A group Soviet-era dissidents published letter Monday, accusing Putin cynicism. We ... consider opening Moscow monument victims political repression untimely cynical, said letter, published Kasparov.ru news portal. It impossible take part memorial events organized authorities say sorry victims Soviet regime, practice continue political repression crush civil freedoms.'],
dtype=object)>}
{'fake': <tf.Tensor: shape=(1,), dtype=int64, numpy=array([0])>}
{'title': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b'BREAKING: DNC HACKER FIRED For Bank Fraud\xe2\x80\xa6Blames Islamophobia \xe2\x80\x9cUltra Right-Wing Media\xe2\x80\x9d'],
dtype=object)>, 'text': <tf.Tensor: shape=(1,), dtype=string, numpy=
array([b'Apparently breaking law scamming government excusable conveniently blame discrimination. And media ignoring illegal activity, stopping getting away anything? After detained bank fraud charges Monday, Imran Awan attorney recently released statement blaming islamophobia ultra right-wing media :This Pakistani family criminal investigation U.S. Capitol Police abusing access House Representatives information technology (IT) system. Abid, Imran Jamal Awan accessed Congressmen Congress people computer networks unauthorized engaged myriad questionable schemes besides allegedly placing ghost employees congressional payroll.Capitol Police revoked Awans access congressional IT system February 2017 major data breach detected. Their access allowed read emails files dozens members, including many serving House Permanent Select Committee Intelligence House Committee Foreign Affairs.Imran Awan, wife Hina, brothers Abid Jamal collectively netted $4 million salary IT administrators House Democrats 2009 2017. Yet absence signs wealth displayed among raise questions. Was money sent overseas something paychecks motivate actions? Both Imran wife traveling Pakistan earlier week carrying $12,000. However, Imran arrested could board plane.Today, Awan attorney released statement claiming attacks Mr. Awan family began part frenzy anti-Muslim bigotry literal heart democracy, House Representatives. He goes saying utterly unsupported, outlandish, slanderous statements targeting Mr. Awan coming ultra-right-wing pizzagate media sitting members Congress. The attorney claims couple traveling see family first time months abruptly unjustly fired. Read more: The Gateway Pundit'],
dtype=object)>}
{'fake': <tf.Tensor: shape=(1,), dtype=int64, numpy=array([1])>}
Evaluate model on the concatenate main model:
model.evaluate(test_data)
22449/22449 [==============================] - 82s 4ms/step - loss: 0.0248 - accuracy: 0.9937
[0.024817833676934242, 0.9936745762825012]
The model reached 99.3% accuracy with around 2% loss function only.
Embedding Visualization
Also, I saw a helpful trick while doing peers assessment that I can do vectorize layer with both feature using this instead of separate the 2 layer: ```python vectorize_layer.adapt(train.map(lambda x, y: x[title] + x[train])) ``` However, I don't think I need to change my whole model for this, accept that it helps with this Embedding Visualization part since it captures all vocabulary.
Word embedding represent word embedded in a vector space. Each words represent an individual vector. This is done in our Embedding layer for our model. Embedding visualization are a 3D representation of this word embedding.
Overview:
- Get the weights from the embedding layer, 3-dimensional collection
- Get the vocabulary from our data prep. Since I had 2 vectorized layer upper (
title_vectorizeandtext_vectorize), I choose usingtext_vectorizeto get the most vocabulary. - Since the weights is in 3D, to plot it in 2D, we need to reduce the data to a 2D representation using Principal Component Analysis (PCA)
- Make an embedding dataframe containing the words, the weight of fake news
x0[:,0]and weights of real newsx1[:,1] - PLOT!
weights = model.get_layer('embedding').get_weights()[0]
text_vocab = text_vectorize.get_vocabulary()
weights
array([[ 0.00394375, -0.01701175, -0.00691615, ..., 0.00852506,
0.00622859, 0.00295982],
[ 0.14989896, 0.18535581, 0.1325196 , ..., 0.02865949,
0.21477613, -0.07494871],
[ 1.6791822 , -1.0778857 , 1.5475878 , ..., -1.4093506 ,
-1.1150874 , -1.543722 ],
...,
[-0.21146128, 0.8576928 , -0.20176668, ..., 0.07602411,
0.93861747, 0.2375286 ],
[ 0.00979571, -0.22537749, 0.03201704, ..., -0.14965881,
-0.06380717, 0.02171237],
[-0.3788106 , 0.67412955, -0.3031203 , ..., 0.40465257,
0.73032963, 0.43246073]], dtype=float32)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
weights = pca.fit_transform(weights)
embedding_df = pd.DataFrame({
'word' : title_vocab,
'x0' : weights[:,0],
'x1' : weights[:,1]
})
embedding_df
| word | x0 | x1 | |
|---|---|---|---|
| 0 | -0.007439 | 0.050368 | |
| 1 | [UNK] | 0.100921 | -0.216544 |
| 2 | trump | 6.290480 | 3.440356 |
| 3 | video | -8.190329 | 5.900573 |
| 4 | to | -4.254767 | 10.526582 |
| ... | ... | ... | ... |
| 1995 | users | 0.554586 | 1.380254 |
| 1996 | uranium | 0.535746 | 0.852877 |
| 1997 | unveils | -0.864867 | -3.116610 |
| 1998 | uncovered | 0.053084 | 0.372793 |
| 1999 | trust | -1.557827 | -2.368656 |
2000 rows × 3 columns
embedding2_df = pd.DataFrame({
'word' : text_vocab,
'x0' : weights[:,0],
'x1' : weights[:,1]
})
fig = px.scatter(embedding2_df,
x = "x0",
y = "x1",
size = list(np.ones(len(embedding_df))),
size_max = 2,
hover_name = "word")
fig.show()
# write_html(fig, 'text_embedding_viz.html')
Through this figure, Top left corner should represent words that usually appears in fake news. However, hovering through each, I can’t really concluded because some words is also stop words like “would, this, and,…” and some big words like “trump, obama, democrats, …”. Hence, from this plot only, I cannot really tell the patterns of fake vs real news.